
I gave this talk a few years ago at Distributed Matters, Berlin in 2015. It was an honor to have Kyle Kingsbury (Aphyr) of Jepsen in the audience, as well as Salvatore Sanfilippo (Antirez) of Redis.
Hi, I’m Mark Nadal, founder and architect of GUN, a VC funded Open Source database. I’m a fan of distributed systems, just like you.

Which is why we are here. My talk is going to explore the dark side of distributed systems, primarily Master-Slave architecture which is the majority of the market. I’ll explain it from ground up, starting with the basics so even newcomers can get up to speed. Then I will be proposing a new distributed design based on Master-Master architecture, a decentralized peer-to-peer setup and going over advanced technical details.

Distributed systems are fundamentally a physics problem, not a computer science one.

One chef, all the work

Distribute the demand across two chefs and you make double the amount of money in half the time.

However, this is not quite yet a distributed system, these two chefs could be competing restaurants such that they are entirely independent actors. What we need is some form of cooperative communication in order for this to be usefully considered a distributed system.

And what is the ultimate purpose of coordination? Well, to survive failure. To be fault tolerant. But coordinating with a dead guy is kind of hard.

So brilliant idea! If we just designate somebody to be the task-master, then they can do all the coordination!

But there is a problem. Coordination is now centralized in the master, what if it fails?

oops.

If any one of the chefs can become the master, then all we need is an odd number of chefs to vote for each other. And we are guaranteed a leader.

But wait. In order to know what the other chefs voted, you have to communicate with them. But if they are dead, you can’t coordinate with them. This problem becomes compounded, because you do not know if they are dead, or if they are just not responding. Because you know, they are actually working making food for customers.

It does turn out that this system works great for specific cases, take 4 chefs for example. Any 1 failure will allow the other 3 to make a majorative vote for a master.

For each

possible

combination.

But what if more than 1 chef fails at a time?

Then we need more chefs. But this causes a permutation edge case which is dangerous. Take this notable example:

There are 3 on each side of the divide, and without knowing if the other side is dead or disconnected you only have two options. A) Sit, wait, and do nothing until you find out if they are dead - which well, you know, might take FOREVER.

Or option B), go ahead and vote to select the next leader. But there is the possibility that you might end up with 2 masters. Ut-oh. This is called a type of....

Split brain.

Oooouch.

This is a great time to bring up the CAP Theorem. You can only choose 2 of the 3 properties, do not let anybody lie to you otherwise. Consistency here generally means “Strong Consistency”, if you want Strong Consistency then...

you absolutely cannot trust the leader election. You cannot choose Option (B), you must choose Option (A) which is to sit and do nothing, locking yourself. Guess what this means. You cannot serve your customers, you are sacrificing High Availability for the sake of Strong Consistency.

Which kinda sucks for you and your customers.

Can we do better?

Not unless you want a massive headache. For me the complexity here lies more in the DevOps work to set this up in the first place than in the algorithm itself - despite that countless implementations of the algorithm have been flawed. Managing this is a nightmare.

All of this is done in the name of Strong or Global Consistency. Part of the controversy today is wanting to challenge whether we should value that at all. For anyone who is wondering why that would be controversial, you would be surprised at how many people get upset over this - so I am calling it out up front.

Now, if we sacrifice Strong Consistency - guess what? Master-Slave architecture is no longer needed. This simplifies things tremendously yet actually turns out to be fairly controversial as well, I have had executives at competing, well known, open source, VC backed startups send me emails of strong disagreement.

But challenging these two tenets is the essence of gun. We are now going to look at the AP side of the CAP Theorem, highly available and partition resilient. Having no central master to coordinate, thus conflict resolution with guns...

in outer space! Why outer space?

Because it is the same thing as getting disconnected on the subway underground. We probably wind up being offline for about 4 to 20 minutes, and guess what? That is how long it takes for light to travel between Earth and Mars. This interplanetary analogy will be helpful for visualizing just how slow and unpredictable the network can be. So we want our apps to work Offline First (so without further ado, here is a
demo of gun surviving these failures). So how does that work? Well, first things first...

Distributed systems are a physics problem, not a computer science one. And the fundamental scientific law is that we cannot send information faster than light.

Thanks Einstein. But you might want to then ask yourself… what is light?

This represents an atom, where the rings correspond to the orbital levels of an electron. Say the electron is at orbital level 5.

When it jumps to orbital level 2 it does not move through space, it teleports.

That teleportation produces a photon. A photon is light. Light is the quantifiable difference in orbital levels.

and that is quantum physics for you. All of quantum mechanics is interested in the difference between electron orbital levels. A field that Einstein hated, yet kinda accidentally birthed. So what does this have to do with us? Well first off...

It means the universe itself is not a strongly consistent system. So why on earth are we trying to violate this? No wonder Kyle Kingsbury’s Keynote showed how many databases fail to live up to this claim, because it is extraordinarily complex and slow to achieve. So let’s go over how a bad network might cause data to become inconsistent.
Remember that a distributed system requires communication. Why are we communicating? Because we are distributing work across space to parallelize it. But communication takes time through space because it is bound by the speed of light. So lets illustrate a basic problem.

We want to synchronize some data. Such that both Earth and Mars see the same thing. We have a “Hello” property that both worlds share and are updating. Earth updates it to “Hello Mars” simultaneously as Mars updates it to “Hello Earth”. What we get is...
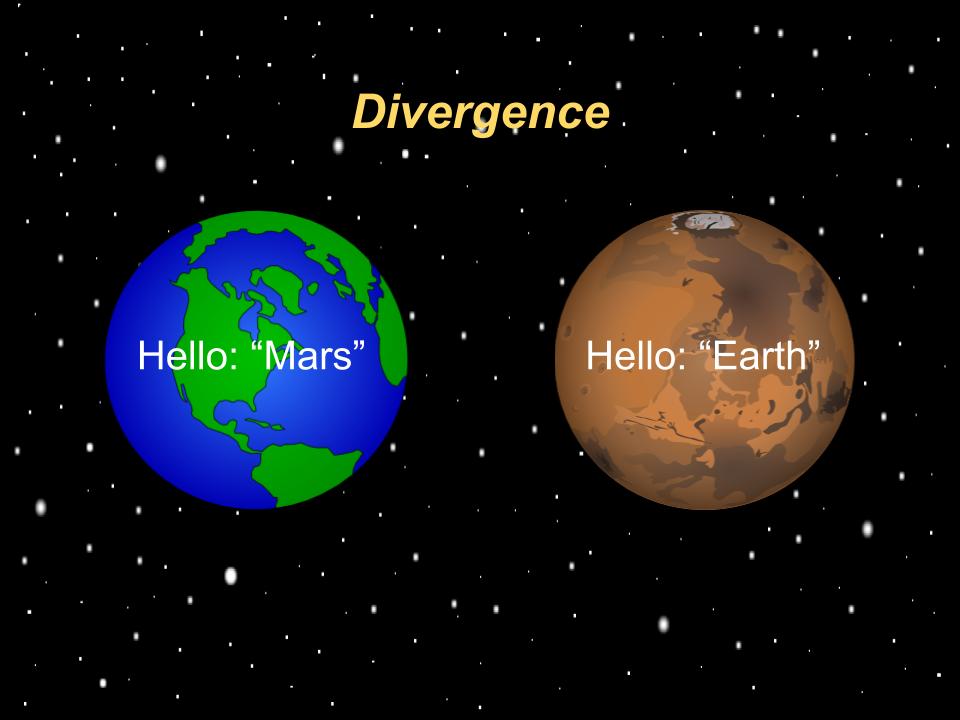
divergence because it took 20 minutes for the update to be sent, and by the time you receive it it overwrites your previous value which is the one you had sent. Now we are out of sync. So how do we get around this? There are some bad options, like...

Like timestamps. Timestamps are bad because anybody can modify their clock so that they are 2 years ahead, which means they will win for the next two years straight. They are easily vulnerable.

The other option is Vector Clocks, but they are vulnerable to resets and collisions.

A quick explanation of how they work is that you always increment past the maximum known vector. So if Alice locally updates her vector with 1 and then 2, but receives an update from Bob at 5, she does not then go from 2 to 3, or 2 to 5, but jumps past 5 to 6. This solves for the timestamp problem, but comes at a cost...

They’re

not

very friendly.

They were invented over 30 years ago when machines were permanent, and they assume a fixed number of peers known in advance. Which isn’t suitable for the elastic ephemeral environments we have today in the cloud where we spawn a 100 machines to handle load and then shut them all down. Clocks get reset and have to catch up, and during this time nothing stops vectors from colliding. So much for conflict resolution.

Well this is dismal. It would be nice to have something with the intuition of timestamps, the simplicity of vectors, and the vulnerabilities of neither. Can we do this? I think yes, but it requires reframing how we look at the problem.

The machine should have a frame of reference, bounded by an open-closed interval. Nothing fancy here, that is like saying from 3 to 5, including 5.

This is the operating state of the machine, everything within this boundary is defined as being valid.

Below the Operating State is the Historical State.

And above the boundary is the Deferred State.

So then the question remains, what happens around and at the boundaries?

Let’s go through this with an example starting at 4 to 8. The algorithm is agnostic to what type of value you use for state, they can be vectors, alphanumeric, timestamps, as long as you are consistent and they have a linear ordering. We’ll use integers here, since they are easy to follow.

What happens if we receive an update at State 9 of “Hello Mars” which is above the boundary of our operating state?

Well, we will process it later when this machine arrives at that state. This is important because it handles the future timestamp dilemma, there are only two possible cases:
A) the peer that sent this update is lying about their timestamp being 2 years in the future so they can “win”, but the clever thing about this approach is that the joke is on them, they will have to wait 2 years to find out whether they were successful or not. This means there is NO advantage to lying, in fact we can prove this in math speak, the only thing we could do is try to be infinitely close to the upper boundary - but the limit on that is 0, which means there is zero advantage. Okay, the other option is...
B) is that the peer is being honest and not malicious, say because it is a GPS satellite which has real drift on its clock - in which case, we still defer processing the request to that later time. Why? Because it is legitimately from the future due to time dilation of Earth’s gravity on us in Einstein’s general theory of relativity. Google spends tens of thousands of dollars maintaining atomic clocks in their datacenters to get around problems like this. Pretty crazy cool stuff, again these are more physics problems than they are anything else.

Alright, next edge case. This one is not nearly as interesting. If we receive an update below our lower boundary.

Well, we record it into an immutable, append-only, data structure so we can always go back to it if need be, like a time-series database. But it does not update our current live view of the data.

And now for the boring case, an update within the boundaries. Most systems just assume an update is valid because they received it within some timeframe, but that is what usually causes a system to go out of sync because it diverges over an invalid boundary. This algorithm instead explicitly checks for that.

And well, if it is within the operating state, we operate on it! This message is considered successfully processed.

And it then becomes the new lower boundary, for this universally unique record. So every record has a different lower boundary, which is changed on every valid atomic update. But the upper boundary remains relative to the machine as a whole - which arbitrarily goes through state changes.

Such that the upper boundary of the state machine goes from 8 to 9. This could be due to a user interaction, like pressing “play” on a video, or it could just be the local clock of the machine, it doesn’t really matter as long as it is consistent. In GUN’s specific implementation of the algorithm, I use timestamps but I’m still calculating conflicts relative to this algorithm so you avoid the vulnerabilities.

Anywho, once we are at state 9, we have to check if there was any deferred updates that correspond to this state. And sure enough, there is and now we can successfully process this message because it is within the valid bounds of the operating state.

In turn, the new lower boundary becomes the upper boundary - closing this system off until the upper boundary changes again.

So let’s zoom in on that and expand the upper boundary so we can deal with the last edge case.

The only remaining edge case, before we go over the weaknesses of this algorithm, is what happens if there is an update that conflicts with the lower boundary itself?

Oh no! Now what? Well, there is a possibility that if the states are exactly the same...

That the values might also be exactly the same. In which case your data is going to converge correctly anyways, it is only the sources that are different.

But in our specific example, we have conflicting values of Earth versus Mars, in which case all we want is a deterministic algorithm that every machine in the entire universe is guaranteed to already have in order for us to converge to the same answer without any extra coordination or communication. I want something...

Naive. Lexical sort achieves that perfectly, purely deterministic and available everywhere.

And as a result the “Hello Earth” update gets bumped to be immediately below the “Hello Mars” update. We do not lose the update, it just gets pushed below the lower open boundary.

And now we are synchronized!

Yay! Well… eventually.

What could possibly go wrong?

Lots of things! The entire algorithm literally only fits on one slide, all it provides is basic synchronization which should cover the vast majority of uses. However, it is no silver bullet.

You obviously get NO STRONG CONSISTENCY. Which means no linearizability and no serializability on concurrent operations because different machines might be at different Operating States.

Running Network Time Protocol will help sync up your machines, but it absolutely does not give you any formal guarantees. Without doing this, GUN’s dirty little secret of latency compensation, might give you a heart attack because sometimes it accidentally simulates latency when there is none. So if you are building a low-latency app, like a game, you’ll want to use NTP or something similar.

But what if you want causality? Where A precedes B which precedes C? You still don’t need Strong Consistency for that, GIT version control manages to do this in a decentralized eventually consistent way by using a Directed Acyclic Graph (DAG). Rather than relying upon some protocol to preserve ordering for you, it is much much safer to explicitly declare it in the data.

But causality can come with side effects, like mathematics? Well then you will need to use some sort of commutative safe operation, like a Convergent Replicated Data Type (CRDT) that does unique counts on your data using identifiers to handle math operations rather than computing on static values, which is how most math is normally done.

And we all know where that leads, to banking! So there is this one big gaping hole, the Double Spending problem. However, a fun fact is that a surprising number of ATMs do not abide by Strong Consistency on this matter despite it being an admittedly appropriate approach for that type of problem. ATMs are vulnerable to double withdrawel. Why? Because banks still ultimately decide that immediate customer satisfaction, aka High Availability, is more important - and I agree, especially if you can track the perpetrator, which if they are withdrawing from their own bank account, you know who they are. But that still might not be good enough for you.

Then what? Well, then you can do as Bitcoin does, create a blockchain ledger. Yes this ultimately requires a network, and there are exploits - like becoming the majority of the worker nodes. But it is still a more elegant solution to problems that people otherwise ascribe to a Master-Slave architecture to fix.

Moral of the story is that the conflict resolution algorithm alone will not solve all your problems, however from it you can add the algorithm you need for your business on top of it. And that is why you are probably here.

Your business has likely reached its limit.

And you want to scale up. But making decisions on these things is tough, and that is why I am here to warn you...

… stay away from Master-Slave architecture or else you will face similar limits again.

Find a system that has reasonable defaults that you can comprehend.

And then choose your business requirements, don’t trust the hand waving of Strong Consistency, albeit popular.

But most importantly.

Remember

that

Let’s include people and solve problems together, without conflict.
Thank you.
gun.eco
